In the product data sheets of almost all storage providers, the term erasure coding (EC) appears more and more often in connection with storage management. All-flash arrays in particular no longer offer RAID. Erasure coding is much better suited for SSDs than conventional RAID-5 or RAID-6. In the article, we explain the basic terms of erasure coding, explain the basic function and go into the advantages and disadvantages of erasure coding.
Erasure Coding is motivated by two distinctive developments in enterprise IT. As the capacity of the hard drives increases, rebuilding a defective RAID takes longer and longer. It takes about 20 hours to completely rewrite a current 16TB disk. In order not to disrupt productive I/O with the RAID rebuild, these rebuilds usually run in the background with low priority. This increases the recovery time accordingly. Rebuild times of 1-2 days are no longer uncommon. In addition, due to the function of RAID-5 or RAID-6, the rebuild of a single disk also means a lot of mechanical stress for all disks in the RAID array. It is quite possible that further disks fail during a rebuild. In environments with many hard disks, people therefore often move away from RAID-6 towards multiple replication. The complete data set is therefore stored redundantly (often 3 times). This requires a corresponding amount of storage media and makes file management more difficult.
Another challenge is the increasing spread of virtual environments and hyper-converged infrastructure (HCI). File systems no longer only span hard drives or SSDs within a system. Distributed file systems provide a consistent namespace across multiple systems. This makes it very easy to z. B. to start a virtual machine on any host within the HCI. RAID only works within a system. This limitation can be removed with erasure coding.
Erasure Coding is motivated by two distinctive developments in enterprise IT. As the capacity of the hard drives increases, rebuilding a defective RAID takes longer and longer. It takes about 20 hours to completely rewrite a current 16TB disk. In order not to disrupt productive I/O with the RAID rebuild, these rebuilds usually run in the background with low priority. This increases the recovery time accordingly. Rebuild times of 1-2 days are no longer uncommon. In addition, due to the function of RAID-5 or RAID-6, the rebuild of a single disk also means a lot of mechanical stress for all disks in the RAID array. It is quite possible that further disks fail during a rebuild. In environments with many hard disks, people therefore often move away from RAID-6 towards multiple replication. The complete data set is therefore stored redundantly (often 3 times). This requires a corresponding amount of storage media and makes file management more difficult.
Another challenge is the increasing spread of virtual environments and hyper-converged infrastructure (HCI). File systems no longer only span hard drives or SSDs within a system. Distributed file systems provide a consistent namespace across multiple systems. This makes it very easy to z. B. to start a virtual machine on any host within the HCI. RAID only works within a system. This limitation can be removed with erasure coding.
Erasure coding. What is it?
Erasure coding belongs to the field of so-called error-correcting codes, sometimes referred to as forward error correction (FEC). Erasure Coding has its scientific background in the mathematical field of linear algebra. These codes have been intensively researched since the 1960s. Such codes were used early on for digital data transmission over long-distance routes. Erasure coding on data carriers was first used commercially in 1982 with the introduction of audio CDs. Erasure codes are also used on DVDs and for DVB-S.
The best-known algorithm is the Reed-Solomon algorithm, named after the two inventors (both mathematicians). There are also a number of other algorithms with various advantages and disadvantages. The research is far from over, the intensive use of erasure coding gives rise to new questions and problems that are worth examining in detail.
However, the basic principle of these codes is always the same: data entering a system is divided into a specified number of equally sized chunks (data chunks). These chunks are then supplemented with redundancy information using mathematical methods (redundancy chunks). Finally, data chunks and redundancy chunks are stored on a storage medium. Separate disks can be provided for redundancy chunks (horizontal codes) or the redundancy information is written to the same disks together with data chunks (vertical codes). The latter is the far more common method.
The best-known algorithm is the Reed-Solomon algorithm, named after the two inventors (both mathematicians). There are also a number of other algorithms with various advantages and disadvantages. The research is far from over, the intensive use of erasure coding gives rise to new questions and problems that are worth examining in detail.
However, the basic principle of these codes is always the same: data entering a system is divided into a specified number of equally sized chunks (data chunks). These chunks are then supplemented with redundancy information using mathematical methods (redundancy chunks). Finally, data chunks and redundancy chunks are stored on a storage medium. Separate disks can be provided for redundancy chunks (horizontal codes) or the redundancy information is written to the same disks together with data chunks (vertical codes). The latter is the far more common method.
Terminology and notation
A typical notation for erasure coding would be something like EC(20,16) or EC(12,9). Expressed mathematically and universally, this is EC(n,k). Where n is the total number of disks in a system, k is the number of data disks. The difference n–k is the number of disks used for redundancy. At the same time, this is also the number of hard disks that can fail in such an array without the data integrity being violated. In practice, the term Erasure Coding 9+3, which is much easier to understand, is becoming more and more common. In this example, Erasure Coding 9+3 is identical to EC(12,9). A total of 12 disks rotate in this network, 3 of which can fail without data being lost.
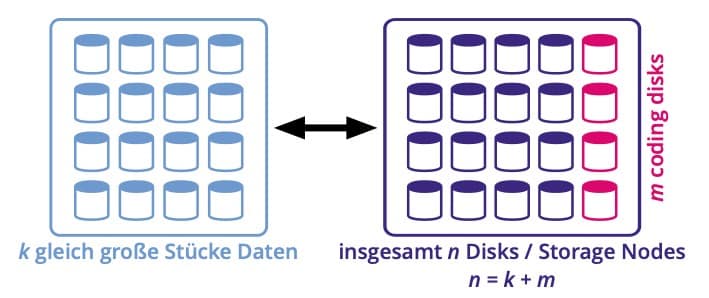
Division of hard disks for erasure coding with the notation EC(20,16)
The ratio of data to redundancy chunks can be set individually within limits depending on the algorithm used. The ratio affects performance, the number of disks that can fail, and the CPU and network performance required in the event of a recovery. In practice, the storage admin can or must rarely specify the ratio individually. In the management interface, manufacturers offer i. i.e. R. several preconfigured erasure codings. The administrator then only has to choose between optimization for speed, optimization for capacity or optimization for reliability and leaves it to the firmware to select the appropriate erasure coding.
The ratio of data to redundancy chunks can be set individually within limits depending on the algorithm used. The ratio affects performance, the number of disks that can fail, and the CPU and network performance required in the event of a recovery. In practice, the storage admin can or must rarely specify the ratio individually. In the management interface, manufacturers offer i. i.e. R. several preconfigured erasure codings. The administrator then only has to choose between optimization for speed, optimization for capacity or optimization for reliability and leaves it to the firmware to select the appropriate erasure coding.
Vorteile des Erasure Coding
Erasure coding can provide more and more flexible redundancy than RAID-5 and RAID-6. We have already briefly outlined this. In addition to the technical advantages, Erasure Coding i. i.e. Usually the procurement of the hardware is also significantly cheaper, because compared to RAID, significantly fewer hard disks are required for the same or better redundancy.
The calculation looks very different with the same usable capacity but triple replication of a RAID-5. For 144 TB usable capacity you need 9 disks here too. In addition, a tenth disk for redundancy in a RAID-5. But because we are writing triple redundantly, you ultimately need 3 x 10 disks = 30 disks. With the same 16TB disks as above, you get 30 x €400 = €12,000 procurement costs. In this example, RAID-5 with replication is two and a half times as expensive to purchase as an equally redundant system based on erasure coding.
Further savings result from the lower space requirement (volume and footprint) in the data center (12 disks vs. 30 disks). This is accompanied by a reduction in power consumption and air conditioning in the server room. Admittedly, the latter only plays a marginal role in the TCO consideration in the overall operation.
A calculation example:
We assume that a storage system offers erasure coding EC(12,9) or 9+3. So in a setup with a total of 12 disks, 3 disks can fail and data integrity is still maintained. This redundancy is not possible with conventional RAID. In order to obtain a redundancy greater than two disks, one would e.g. B. fall back on a RAID-5 with three replicas. We further assume that we are using modern 16TB hard drives. These records currently (September 2020) cost around €400 each. The EC(12,9) has nine data disks, i.e. 9 x 16TB = 144 TB usable for the file system. A total of 12 plates must be procured, i.e. 12 x €400 = €4,800.The calculation looks very different with the same usable capacity but triple replication of a RAID-5. For 144 TB usable capacity you need 9 disks here too. In addition, a tenth disk for redundancy in a RAID-5. But because we are writing triple redundantly, you ultimately need 3 x 10 disks = 30 disks. With the same 16TB disks as above, you get 30 x €400 = €12,000 procurement costs. In this example, RAID-5 with replication is two and a half times as expensive to purchase as an equally redundant system based on erasure coding.
Further savings result from the lower space requirement (volume and footprint) in the data center (12 disks vs. 30 disks). This is accompanied by a reduction in power consumption and air conditioning in the server room. Admittedly, the latter only plays a marginal role in the TCO consideration in the overall operation.
Jede Medaille hat zwei Seiten
If a disk or storage node fails, data must be reconstructed. For this purpose, various still intact data chunks as well as intact redundancy chunks are read and the missing data is calculated from them according to the erasure coding algorithm. Recovery with Erasure Coding is slightly more computationally intensive than is the case with traditional RAID. Depending on the algorithm, the restore can be particularly I/O intensive because many chunks may need to be read. In the case of distributed file systems, this fact must be taken into account when dimensioning the network connections.
Newer implementations in the field of HCI and distributed file systems use so-called Locally Repairable Codes (LRC). Redundancy is created and distributed in such a way that e.g. For example, the failure of a single disk within a storage node can also be reconstructed within the affected storage node. There is therefore no additional network traffic in the event of a restore. Chunks from neighboring nodes only have to be read if several disks or a complete storage node fails. During a RAID rebuild, a failed and replaced hard disk is described identically in blocks with the status before the failure. With erasure coding, the redundancy information is stored in a distributed system. During the rebuild, the data and redundancy chunks missing due to a disk failure can be recalculated and written to the remaining disks in the system. As a result, the I/O performance of a single hard disk is no longer the bottleneck during a rebuild, as is the case with RAID.
Many enterprise storage systems now use erasure coding. All cloud providers also rely on erasure coding for their storage products. At Cristie Data, we also use erasure coding, e.g. with our CLOUDBRIK offers.
Newer implementations in the field of HCI and distributed file systems use so-called Locally Repairable Codes (LRC). Redundancy is created and distributed in such a way that e.g. For example, the failure of a single disk within a storage node can also be reconstructed within the affected storage node. There is therefore no additional network traffic in the event of a restore. Chunks from neighboring nodes only have to be read if several disks or a complete storage node fails. During a RAID rebuild, a failed and replaced hard disk is described identically in blocks with the status before the failure. With erasure coding, the redundancy information is stored in a distributed system. During the rebuild, the data and redundancy chunks missing due to a disk failure can be recalculated and written to the remaining disks in the system. As a result, the I/O performance of a single hard disk is no longer the bottleneck during a rebuild, as is the case with RAID.
Many enterprise storage systems now use erasure coding. All cloud providers also rely on erasure coding for their storage products. At Cristie Data, we also use erasure coding, e.g. with our CLOUDBRIK offers.
